Financial services institutions are rightly using the latest technologies to modernize trading, real-time analytical decision-making and business operations. However, it’s just as important to ensure the various components form a resilient platform that can withstand the tribulations of black swan events.
Recent troubles and outages have shined a light on the vulnerability of critical platforms and the necessity for new tools and processes that ensure they will stay strong. COVID-19 isn’t the only culprit. Brexit, interest-rate announcements, large market movements and negative oil prices have all strained and even broken critical platforms – exposing weaknesses that were always there.
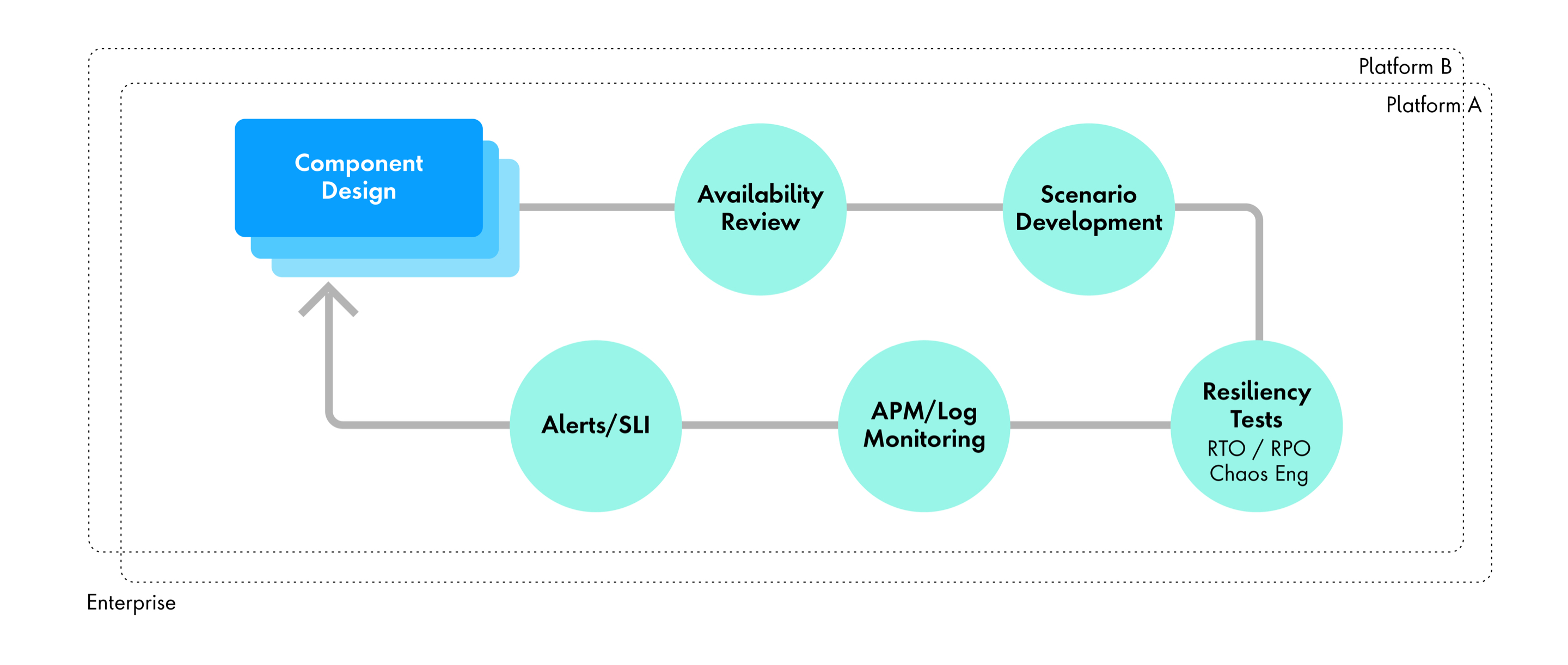
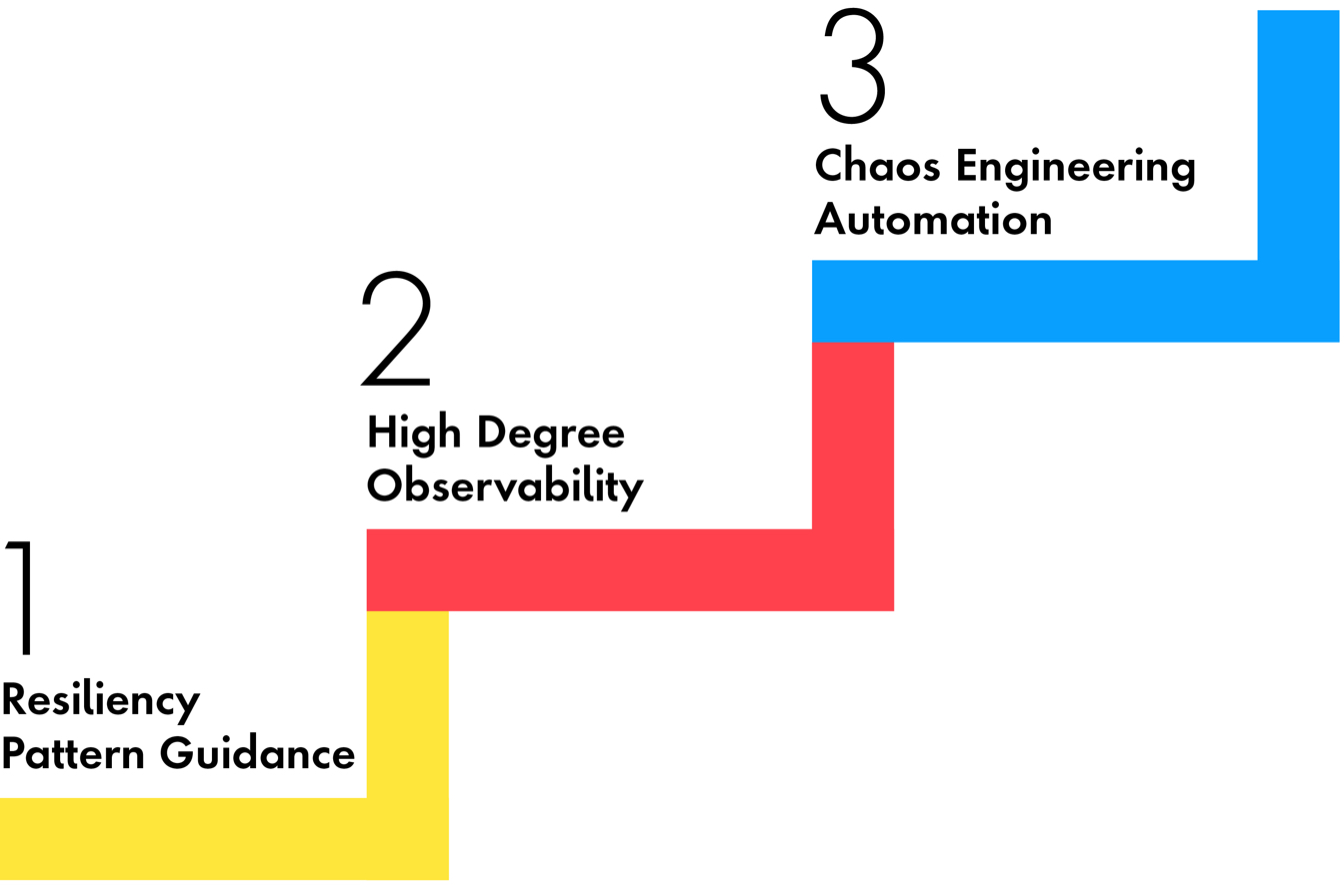
Site Reliability Engineering (SRE) is the formal engineering method for creating reliable software systems. Within that discipline, Publicis Sapient offers a solution that integrates critical platforms into chaos testing scenarios and tracks their fortitude with advanced monitoring tools.