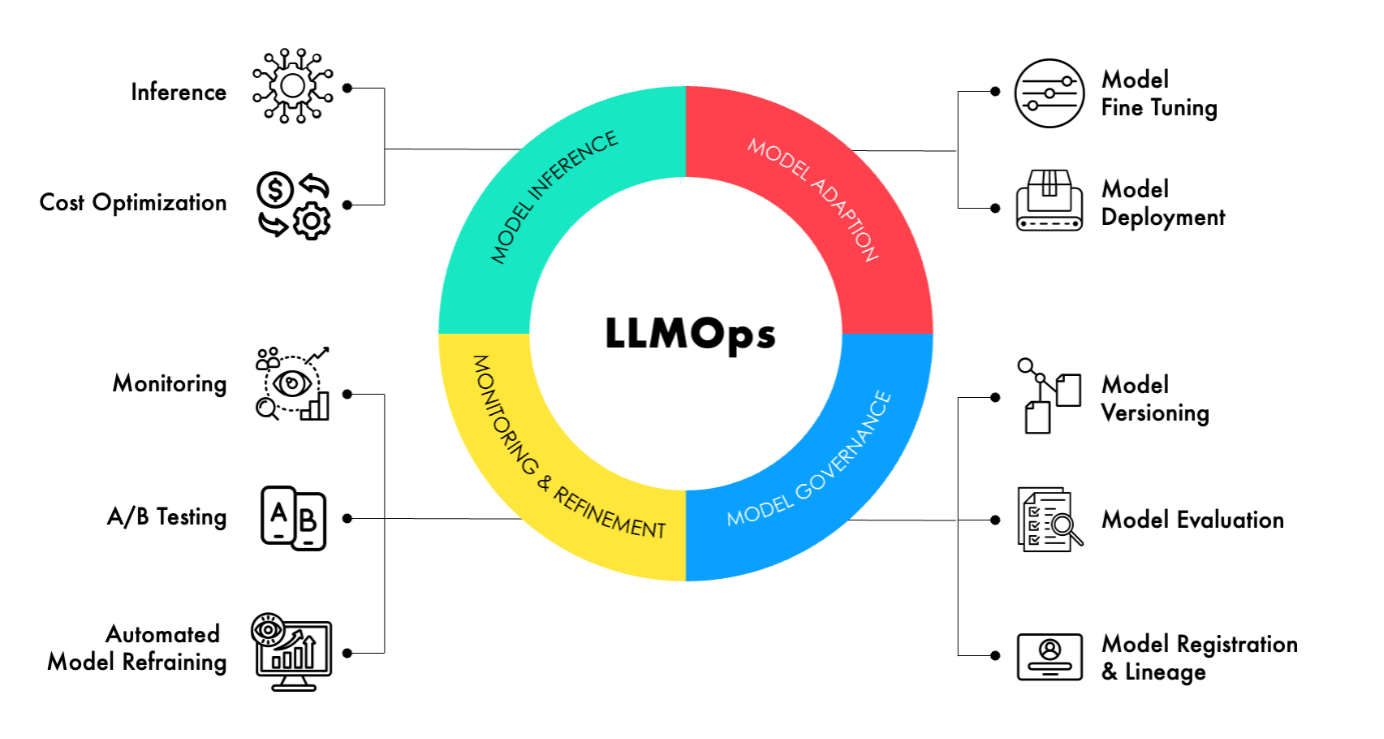
Foundation models can be fine-tuned for specific tasks using private labeled datasets in just a few steps. Amazon Bedrock supports fine-tuning for a range of FMs. A second way some models (Amazon Titan Text models in particular) can be adapted is using continued pre-training with unlabeled data for specific industries and domains. With fine-tuning and continued pre-training, Amazon Bedrock makes a separate copy of the base FM that is accessible privately, and the data is not used to train the original base models. The FMs can be equipped with up-to-date proprietary information using Retrieval Augmented Generation (RAG), a technique that involves fetching data from your own data sources and enriching the prompt with that data to deliver more relevant and accurate responses. Knowledge Bases for Amazon Bedrock automates the complete RAG workflow, including ingestion, retrieval, prompt augmentation, and citations, removing the need for you to write custom code to integrate data sources and manage queries. Content can be easily ingested from the web and from repositories such as Amazon Simple Storage Service (Amazon S3). Once the content is ingested, Amazon Bedrock Knowledge Bases divides the content into blocks of text, converts the text into embeddings, and stores the embeddings in your choice of vector database. Continuously retraining FMs can be compute-intensive and expensive. RAG addresses this issue by providing models access to external data at run-time. Relevant data is then added to the prompt to help improve both the relevance and accuracy of completions.
However, there can be some scenarios where FM fine-tuning might require aspects of explicit training. In those scenarios, Amazon SageMaker Ground Truth can be leveraged for data generation, annotation, and labeling. This can be done either using a self-service or AWS-managed offering. In the case of the managed offering, the data labeling workflows are set up and operated on your behalf. Data labeling is completed by an expert workforce. In a self-serve setup, a labeling job can be created using custom or built-in workflows, and labelers can be chosen from a group. Another option is using Amazon Comprehend for automated data extraction and annotation for natural language processing tasks. AWS Data Exchange also provides curated datasets that can be used for training and fine-tuning models.
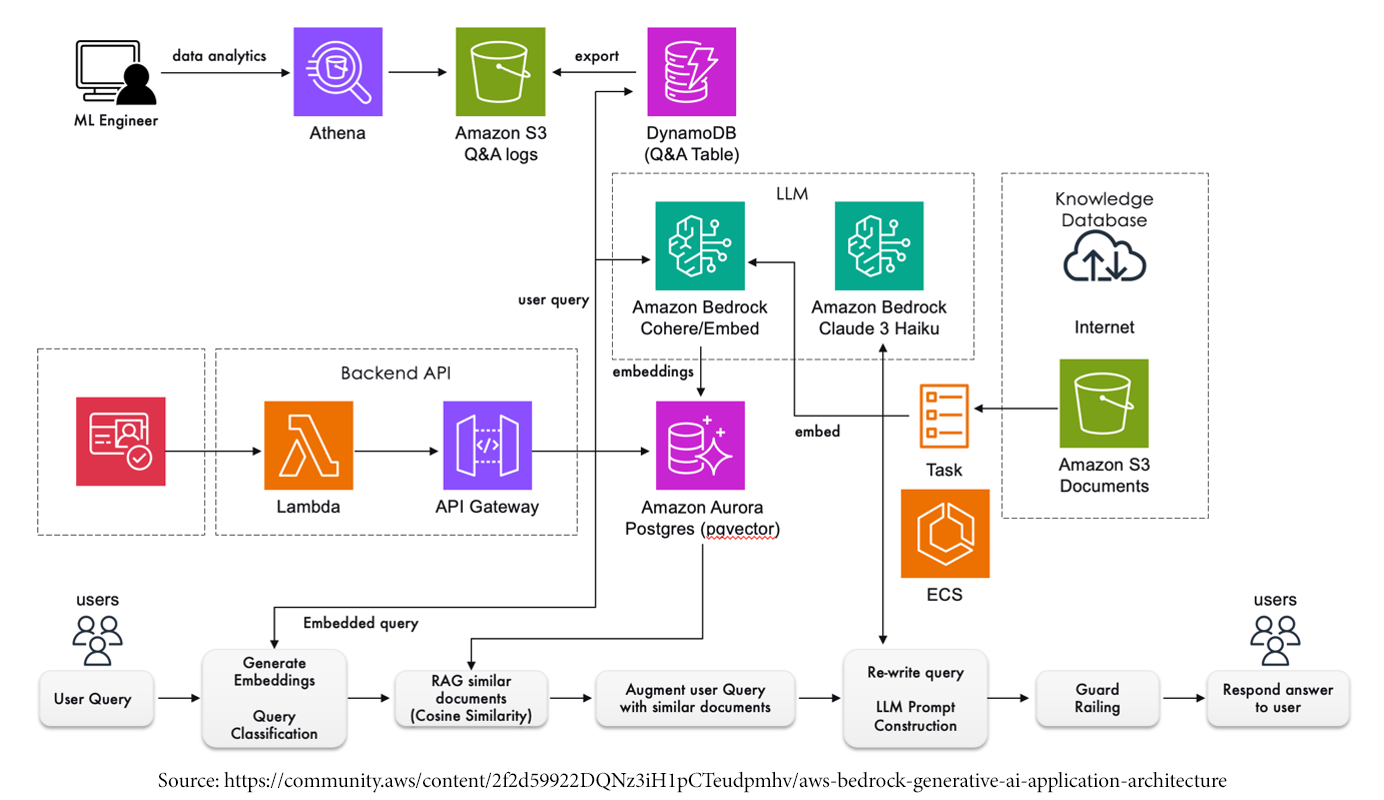
A common pattern for storing data and information for Gen AI applications is converting documents, or chunks of documents, into vector embeddings using an embedding model and then storing these vector embeddings in a vector store/database. Customers want a vector store option that is simple to build on and enables them to move quickly from prototyping to production so they can focus on creating differentiated applications. Here are a few options to consider:
- Amazon Vector Engine for OpenSearch Serverless: The vector engine extends OpenSearch's search capabilities by enabling you to store, search, and retrieve billions of vector embeddings in real time and perform accurate similarity matching and semantic searches without having to think about the underlying infrastructure.
- Integration with existing Vector stores like Pinecone or Redis Enterprise Cloud.
- Amazon Aurora PostgreSQL and Amazon RDS with pgvector extension.
The appropriate service needs to be configured based on scalability and performance requirements.
The serverless feature of Amazon Bedrock takes away the complexity of managing infrastructure while allowing easy deployment of models through a console. For conventional ML algorithms, Amazon SageMaker also provides robust model deployment capabilities, including support for A/B testing and auto-scaling. AWS Lambda can be used for serverless model serving. Amazon ECS and Amazon EKS offer container-based deployment options for ML models, providing flexibility and scalability.